
Posted in: Community > MA Screening Quant Strategy: A Harness Engineer Approach in Practice
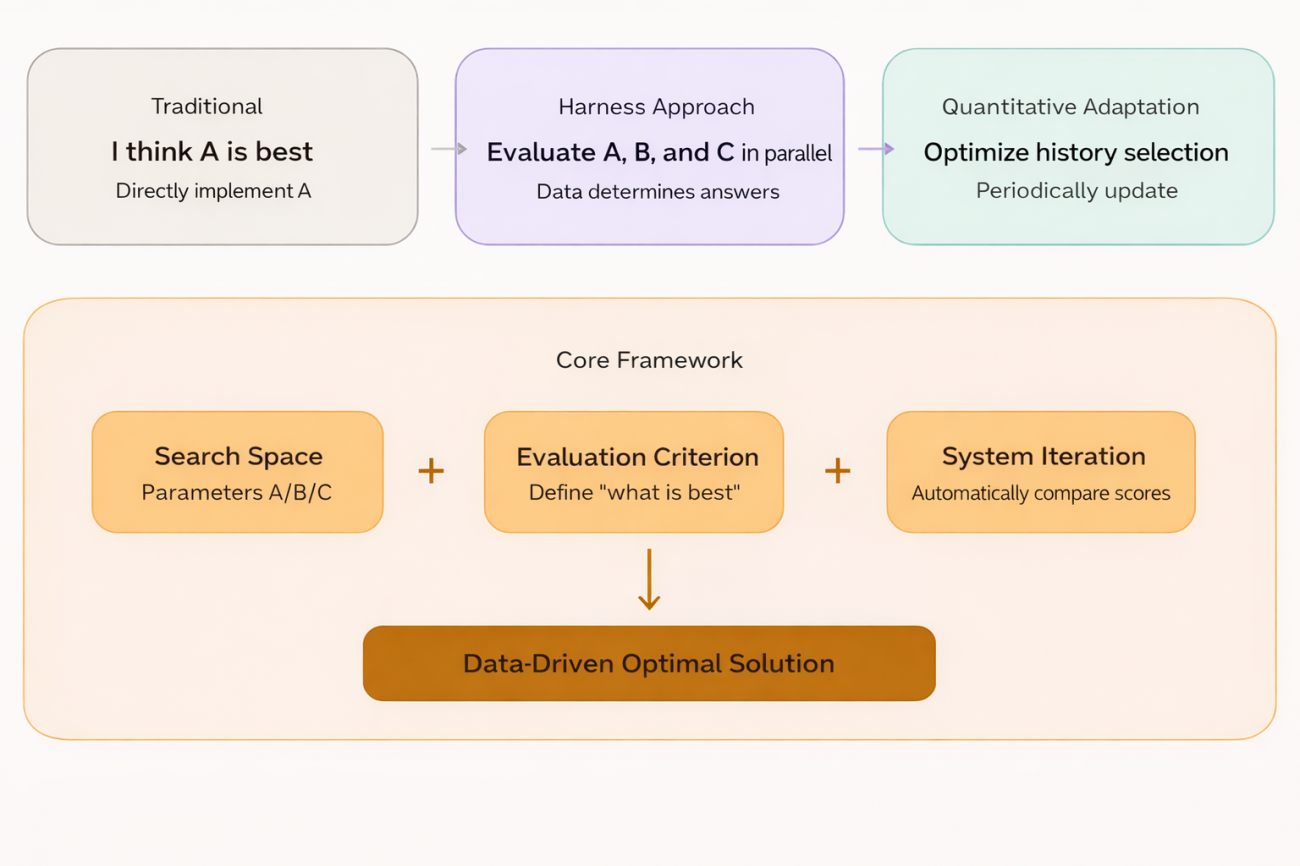
Intro: The Harness Engineer Mindset
Lately in the AI/ML engineering community, a way of thinking has been getting increasingly discussed — Harness Engineer.
The core idea is simple:
Instead of coming up with an answer by gut feeling, build a harness and let the data and experiments find the answer for you.
The traditional engineer’s approach is: I believe parameter A is better, so I’ll write code to implement A. The Harness Engineer’s approach is: I don’t know whether A, B, or C is better, so I’ll build a framework that runs A, B, and C in parallel and let the data tell me the answer.
The engineer is responsible for defining the search space and the evaluation criteria; the system is responsible for automatically searching the space for the optimum. In ML this corresponds to walk-forward optimization and AutoML. In quant trading, there’s actually a natural place for this idea to land.
“Demon Coins”: Where the Trend Is Most Visible
In the crypto perpetual contract market, there’s a category of tokens worth paying special attention to — the high-volume “demon coins.”
These tokens share several traits:
- Highly concentrated capital — whale/market-maker behavior is unmistakable
- Persistent trends — once a move gets going, it tends to last
- High volatility — some high-volume tokens during specific periods exhibit strong trend behavior, where MA strategies historically perform reasonably well on these symbols
For exactly these reasons, using the classic dual-MA crossover strategy on such tokens is a plain but sensible entry point. Fast line crosses above the slow line — trend is starting, go with it. Fast line crosses below the slow line — trend is reversing, get out. The logic is simple, but on symbols with clear trends, historical performance usually isn’t bad.
There’s only one problem: which tokens are demon coins? Which MA parameter set should be used?
If you try to answer these two questions by hand, it’s too subjective — a different person could arrive at completely different answers. And the market is dynamic: today’s demon coin isn’t necessarily tomorrow’s, and today’s effective parameter combination could fail tomorrow.
This is exactly where the Harness Engineer mindset comes in.
Rather than hand-picking tokens and hand-tuning parameters, hand both problems off to the framework — define the evaluation criteria, let historical data run itself through the candidate space and produce the answer. The human only decides the criteria for good vs. bad; the system handles the rest.
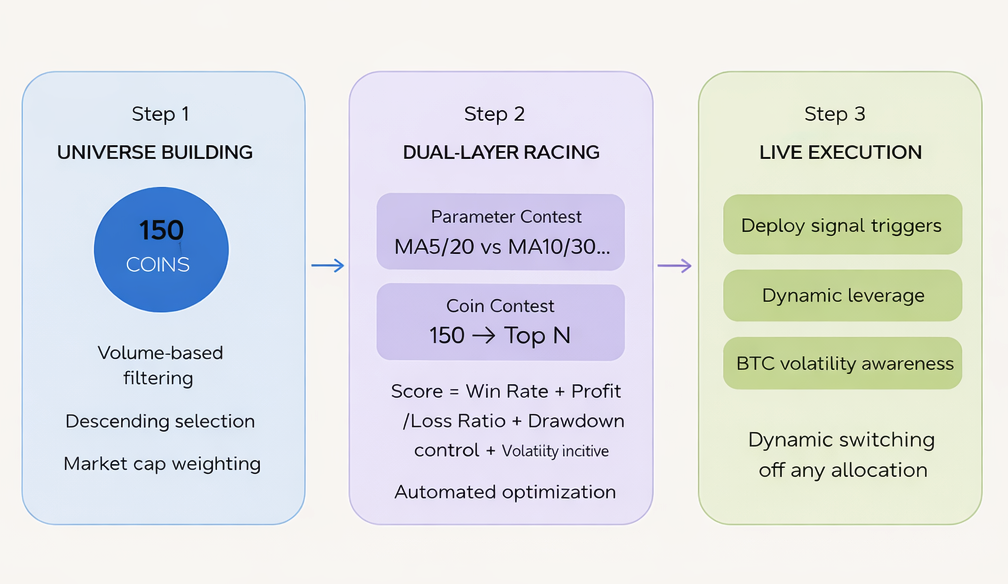
On this basis, the entire strategy is designed as a rolling screening framework, operating in three layers.
Strategy Architecture: A Two-Stage Horse Race
Layer 1: Building the Candidate Pool
From all contract symbols across the market, take the top 150 by USD trading volume as the candidate pool.
Why volume? Because that’s where capital is most concentrated, trends form most readily, and demon coins cluster most densely. This step involves no subjective judgment — the market’s capital votes directly: whoever trades the most gets into the pool.
const filtered = tickers
.filter(t => t.Symbol.endsWith('USDT.swap'))
.map(t => ({ symbol: t.Symbol, quoteVolume: t.Last * t.Volume }))
.sort((a, b) => b.quoteVolume - a.quoteVolume)
.slice(0, topN)
.map(t => t.symbol);
Logic is very direct: filter USDT perpetual contracts, compute USD volume, sort descending, take the top N. No subjective calls — capital votes with its feet.
Layer 2: Two-Stage Horse-Race Selection
This is the core of the whole strategy, and where the Harness mindset shows up most clearly.
The correct order of execution is:
⚠️ Note: Using the best-parameter score as a proxy for a token’s “capability” itself carries some overfitting risk — the parameters that performed best on history won’t necessarily perform equally well in the future. This limitation is discussed further in the second half of the article.
Backtest process
For every token in the candidate pool, run multiple MA parameter combinations in parallel. Each combination runs independently on historical K-lines, simulating real crossover entries and exits:
// Iterate: each coin × each parameter combo
for (const params of maParamsList) {
const bt = backtest_MA(records, params.fast, params.slow);
// Each backtest independently yields: win rate, profit factor, max drawdown, signal count
}
Each backtest’s core logic is standard dual-MA crossover:
const crossUp = fastMA[i-1] <= slowMA[i-1] && fastMA[i] > slowMA[i];
const crossDown = fastMA[i-1] >= slowMA[i-1] && fastMA[i] < slowMA[i];
if (crossUp) position = { side: 'long', entryPrice: records[i].Close };
if (crossDown) position = { side: 'short', entryPrice: records[i].Close };
Composite score
Once backtests complete, each parameter set’s results get scored. The scoring is made of two parts:
Normalized weighted score (weights sum to 0.80):
const score =
Math.min(bt.winRate * 100, 100) * 0.30 // win rate, capped at 100
+ Math.min(bt.profitFactor * 20, 60) * 0.30 // profit factor, capped at 60
+ Math.max(0, 1 - bt.maxDrawdown / maxMDD) * 100 * 0.20 // max drawdown control
+ volPct * volPctBonus // volatility-percentile bonus
Volatility-percentile bonus: the last term volPct × volPctBonus (default coefficient 10) is a bonus separate from the weighted system, used to break ties by favoring tokens whose current volatility sits at a higher historical percentile — these tokens tend to be more active trend-wise.
Note that all these weights and bonus coefficients are heuristic — they weren’t derived through optimization. They can be further tuned based on actual market conditions.
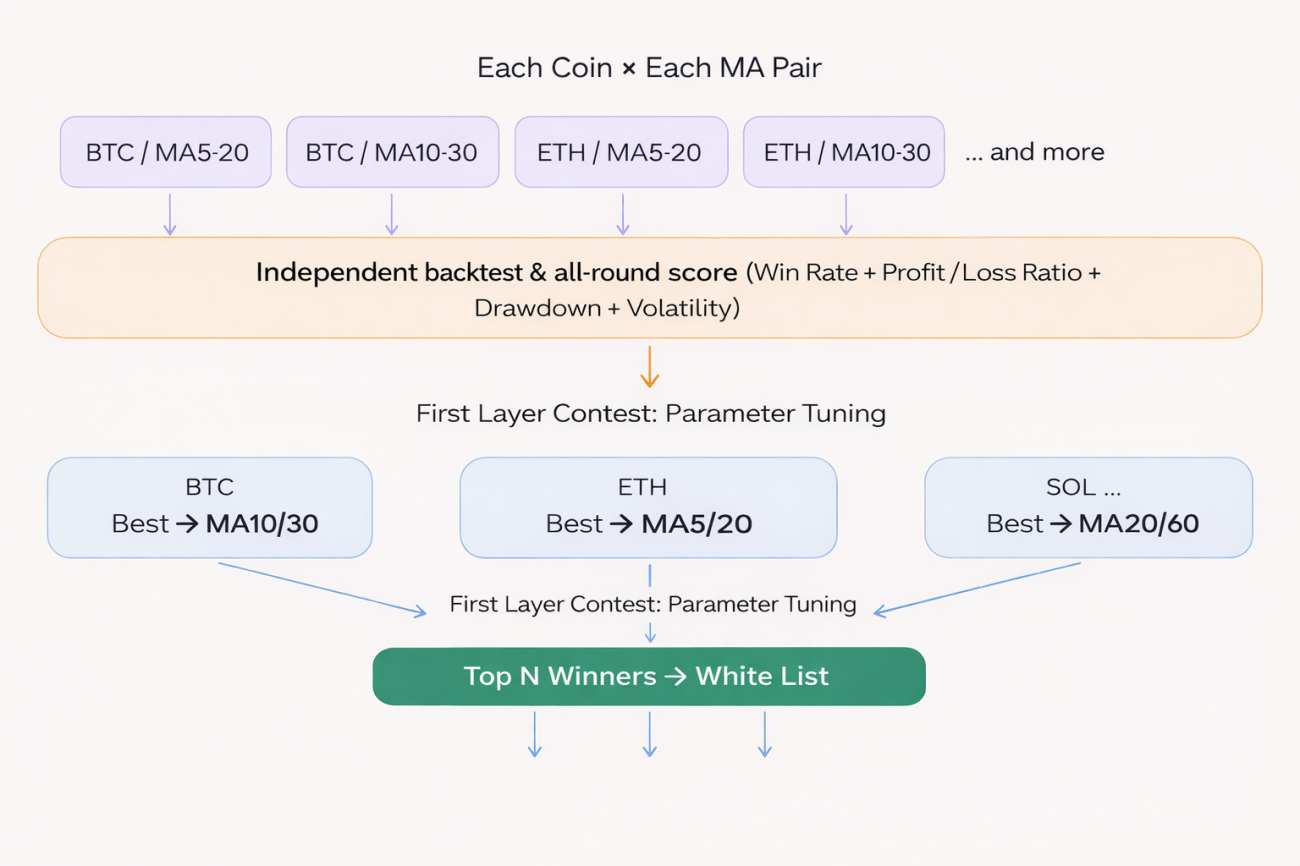
Stage 1 Competition: Parameter Competition
For a given token, multiple parameter sets each get their own score. The highest-scoring set becomes that token’s representative score and its best parameters:
if (score > bestScore) {
bestScore = score;
bestResult = bt;
bestParams = params; // record the best-performing parameter combo so far
}
Stage 2 Competition: Token Competition
All tokens bring forward their best score. These are sorted, and the Top N enter the whitelist:
results.sort((a, b) => b.score - a.score);
const whitelist = results.slice(0, topCoins).map(r => r.coin);
The final output is: for each whitelisted token, its own dedicated best MA parameters — not a single parameter set applied across the board.
Layer 3: Live Execution and Risk Controls
Use the screened configuration for live trading, with multiple risk-control layers stacked on top:
Signal triggering: continuously detect MA crossovers on whitelisted tokens — golden cross → long, death cross → short:
const crossUp = fastPrev <= slowPrev && fastCur > slowCur;
const crossDown = fastPrev >= slowPrev && fastCur < slowCur;
if (crossUp) longList.push(sym);
if (crossDown && allowShort) shortList.push(sym);
Trailing take-profit: activates once floating profit hits a trigger threshold, with the pullback threshold tightening dynamically as floating profit grows. The three tiers are heuristic — the core idea is: the higher the floating profit, the lower the tolerance for pullback, locking in gains already made:
function getDynamicTrailDrawdown(maxPnl) {
if (maxPnl >= 7) return 3; // high profit, tighten pullback tolerance
if (maxPnl >= 4) return 2;
return 1.5; // lower profit, give the move a bit more room
}
Market regime awareness: detect BTC’s volatility percentile — high-volatility environments automatically scale down position sizing, and extreme regimes outright disable shorting:
if (marketState === 'volatile') positionScaleDown = 0.5;
else if (marketState === 'high_vol') positionScaleDown = 0.8;
else if (marketState === 'low_vol') positionScaleDown = 0.7;
The entire screening pipeline re-runs on a rolling schedule — not sticking to any single configuration, but dynamically updating the whitelist and parameters as the market evolves.
Underlying Assumption: Trend Persistence
For this framework to hold up, it depends on one core assumption:
Tokens and parameters that performed well in the recent past have some degree of continuity in the near future.
This isn’t mysticism — there’s real market logic supporting it. Capital inertia, continuation of market sentiment, and coherence in whale behavior all keep trends valid within some time window.
But to be honest: this assumption hasn’t gone through rigorous statistical validation — it’s more of an empirical judgment. Whether the framework continues to work in live trading ultimately has to be verified against real trading data.
How This Differs from a Real Harness Engineer Setup
This has to be said plainly.
This strategy has the shape of a Harness, but compared to a real Harness Engineer system, the gaps are obvious:
| Dimension | Real Harness | This Strategy |
|---|---|---|
| Sample split | Train + validation + holdout test | Full-history backtest, no out-of-sample validation |
| Overfitting defense | Explicit generalization checks | Relies on parameter diversity — partial hedge, incomplete |
| Experiment isolation | Each variant runs independently, no interference | Shares the same K-line data, implicit coupling |
| Deployment gate | Must pass validation before going live | Highest score goes live directly, no secondary check |
| Layer-wise error accumulation | Each layer evaluated independently | Both horse-race stages based on historical best — errors compound |
The core gap: a real Harness keeps asking “does this result still hold out-of-sample?” — whereas the “best” coming out of this strategy’s two-stage horse race is, fundamentally, just historical best. Parameter-level overfitting stacked on top of token-level overfitting — whether that carries forward is a permanently open question.
Closing: Carving Marks on a Moving Boat — Still Worth Trying?
In the quant world, prediction has always been incredibly hard.
Plenty of people will say: picking parameters from historical data and deploying them live is essentially carving a notch on a moving boat to mark where your sword fell into the water. The sword’s already sunk; the mark you carved on the boat won’t help you find it. Markets change, effective parameters stop working, today’s demon coin gets boring tomorrow, yesterday’s optimal MA is today’s noise.
This critique isn’t without merit.
But that said — the experiments worth running still have to be run.
The essence of quant isn’t finding an answer that’s permanently correct — it’s systematically improving your win rate under uncertainty. Even if you’re carving notches on a moving boat, you still need a boat and a mark first. Locating the strategy (the boat) is itself the beginning of quant.
Of course, the framework itself doesn’t guarantee profit. Having the framework is just a starting point — the real value is in continuous execution and iteration: the whitelist can be adjusted, scoring weights can be changed, the parameter space can be expanded, take-profit and stop-loss logic can be improved. Every adjustment is a new experiment, and every experiment pushes this framework closer to a real Harness.
The path is walked, not thought.




