Recently, I saw that there is no relevant information about Python crawlers in the community and library, based on the spirit of all-round development of QUANT, I learned some concepts and knowledge related to crawlers simply. After some understanding, I found that the “pit” of “crawler technology” is quite large. This article is just for the preliminary study of “crawler technology”. Do the simplest practice on the FMZ Quant Trading platform about the crawler technology.
Demand
For those who like to subscribe new shares, they always hope to get the information of currency on the exchange at the first time. It is obviously unrealistic for people to monitor the exchange website all the time. Then you need to use the crawler script to monitor the exchange announcement page and detect new announcements so that you can be notified and reminded at the first time.
Preliminary Exploration
A very simple program is used to get started (a really powerful crawler script is far more complex, so take your time first). The program logic is very simple. It allows the program to access the announcement page of the exchange constantly, parse the obtained HTML content, and detect whether the specific label content is updated.
Implementation code
You can use some useful crawler frameworks. However, considering that the requirements are very simple, you can write them directly.
The following python libraries need to be used:Requests, which can be simply understood as a library used to access web pages.Bs4, which can be simply understood as a library used to parse HTML code on web pages.
Code:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # Binance announcement page address
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # Use the requests library to access the url, i.e. the address of the Binance announcement page
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # Return page content text if access is successful
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # Parse web text into objects
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # Find a specific tag, get href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # Get the content in this tag
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # A new announcement is generated when a label change is detected
Log("New Cryptocurrency Listing update!") # Print the prompt message
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
Operation


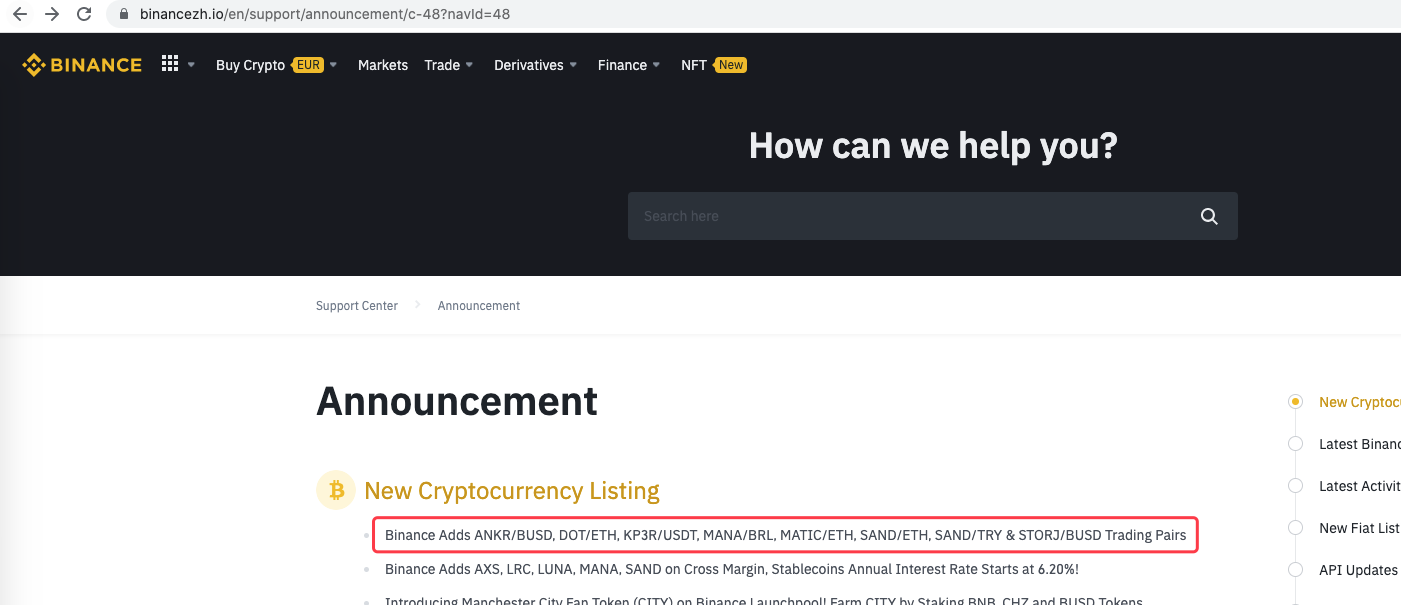
It can be extended, for example, when a new announcement is detected. Analyze the new currency in the announcement, and place an order automatically to subscribe new shares.